AI的快速发展对数据存储提出了前所未有的挑战,要求海量数据和高性能存储。企业需构建高效、可靠的存储基础设施,如全闪存存储、数据湖等,以满足AI的需求。同时,还需应对数据安全、隐私保护和成本控制等问题。IT团队在有限资源下必须平衡性能、扩展性、安全性和简便性。选择适合业务特点的存储解决方案对加速AI项目落地和提高数据管理效率至关重要,这也是企业应对AI时代的核心任务之一。
概述 #
AI正以前所未有的速度渗透各行各业,其潜力已毋庸置疑。众多组织将其视为提升竞争力的关键,纷纷加大对AI的投入。
然而,AI的价值实现并非一蹴而就。组织需要仔细评估资源需求,尤其是如何有效管理信息资产。随着AI应用的深入,企业面临着将宝贵数据高效引入AI模型的挑战。如何平衡数据访问与安全,如何满足AI环境的独特需求,成为组织IT团队亟待解决的问题。
云端AI开发的便捷性与企业对数据主权的重视形成了鲜明对比。企业IT部门必须为AI团队提供本地开发环境,这无疑增加了IT部门的工作复杂性。如何在有限的资源下,为AI团队构建高效、可靠的基础设施,成为IT部门面临的新课题。
要满足不断增长的AI需求,选择合适的技术至关重要。除了强大的计算资源和AI工具,高效、可扩展的存储解决方案更是重中之重。这不仅能加速模型训练,降低成本,还能显著提升数据科学家的工作效率。IT部门作为AI基础设施的提供者,必须深入理解AI团队的需求,并提供最优解决方案。
AI对基础设施的新要求 #
AI基础设施对于传统IT团队而言是一片全新的疆域。团队可能在GPU等加速硬件、异构系统架构方面经验不足。尽管团队在数据存储和管理上有深厚积累,但对AI的工作原理和应用场景却可能知之甚少。AI环境通常处理来自多个异构数据源的信息,这些数据需要经过数据工程师的精心整理,才能用于模型训练。这些数据可能来自关系型数据库、文件系统、甚至外部数据源,且格式不统一、存储位置分散。数据的规模庞大,进一步增加了处理的复杂性。
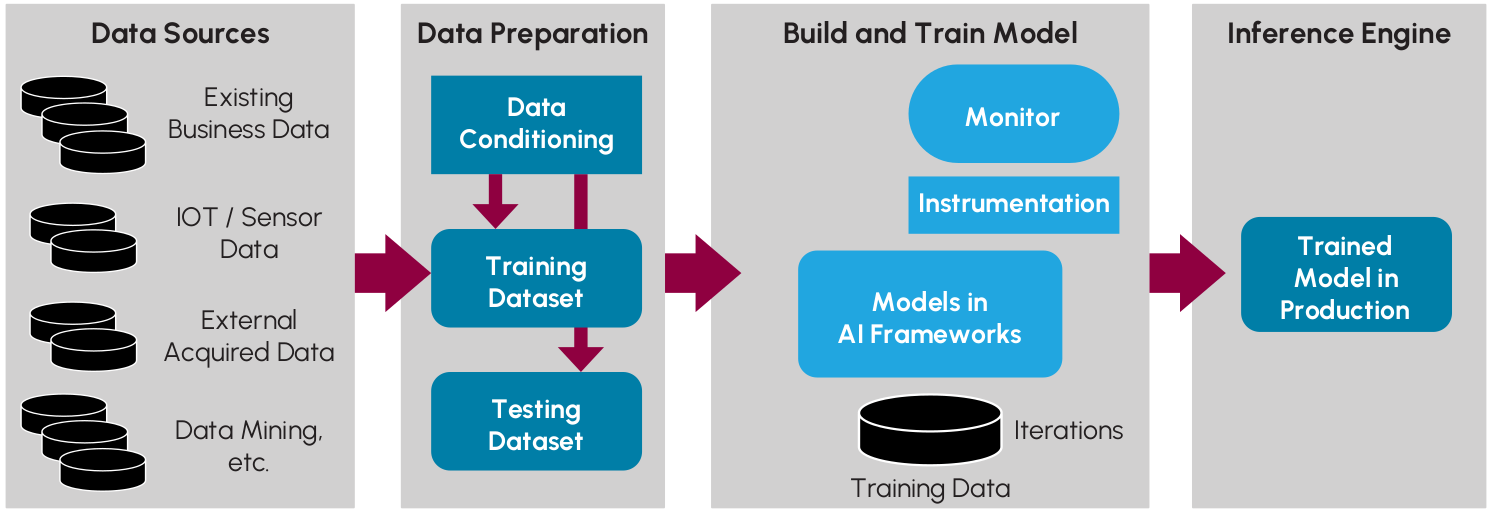
数据科学团队负责数据的质量和可用性,但IT部门需要提供坚实的技术基础。数据科学团队要求数据能够即时获取,这对存储系统的性能提出了极高的要求。IT团队在选择存储系统时,需要充分考虑数据访问的I/O特性,并优化与GPU或加速器的互联。此外,数据复制、保护和数据库访问等数据服务也是IT基础设施需要提供的关键功能。
目前,AI开发主要集中在公有云平台上。企业通常会选择已有的基础模型,并利用私有数据进行微调,以创建定制化的AI模型。生成式AI中的检索增强生成(RAG)就是一个典型的例子。RAG通过引入新的、定制化的数据,提升了大型语言模型的准确性、时效性和相关性。
由于公有云在AI开发中占据主导地位,数据科学团队对云端存储系统的性能、可用性和保护机制的重视程度往往不够。因此,IT部门需要深入了解业务需求,评估各种存储解决方案,并向数据科学团队清晰地传达本地部署的优势。在私有环境中,IT部门需要考虑数据的存储位置、访问方式、以及数据保护和安全合规性等方面的问题。
随着AI应用的不断深入,企业开始将AI工作负载从公有云迁移到本地数据中心,或者采用混合云部署模式。一方面,公有云的高昂成本在规模化部署时会成为企业的负担;另一方面,数据安全、隐私保护以及对资源的掌控需求也在推动企业向本地化迁移。此外,新型的基础设施和存储即服务(SaaS)解决方案的出现,
AI本地化存储的特性 #
用于训练AI模型的数据来源广泛,包括结构化和非结构化数据。这些数据通常存储在数据湖或数据湖仓中,以满足AI/ML项目对大规模、高性能存储的需求。数据工程师创建的训练数据集是AI模型训练的基石。数据科学团队对存储系统的性能要求极高,包括大容量、高带宽和低延迟。
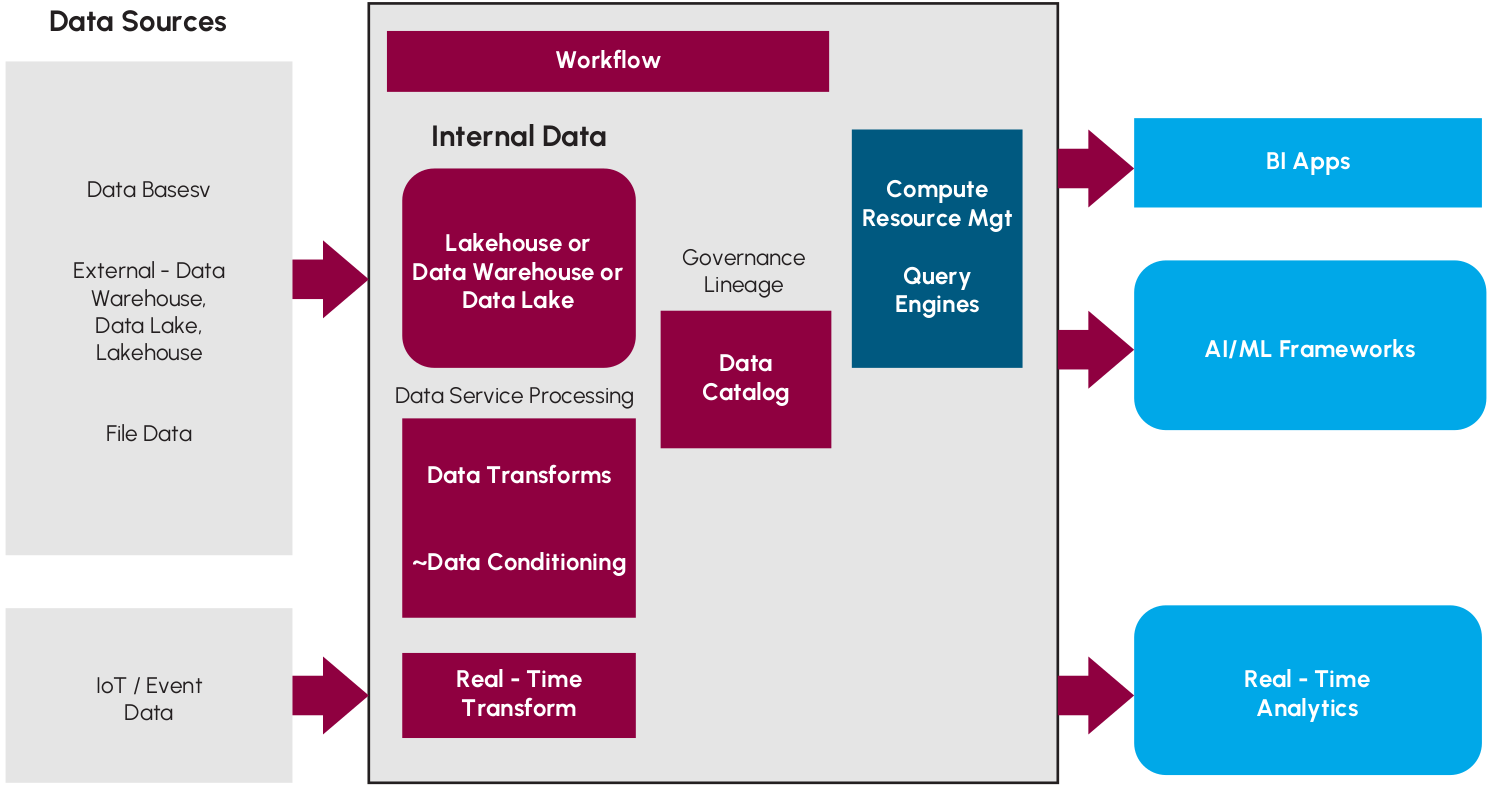
随着AI的发展,对存储系统的需求也日益多样化。全闪存存储凭借其性能一致性,成为AI存储的首选。AI环境在不同发展阶段对存储系统的需求也不同:
初始/成熟阶段:需要兼具高性能文件存储和对象存储。生产级:需要大规模容量的文件和对象存储,同时保持高性能。
IT基础设施团队和AI平台架构师对存储系统都有各自的关注点。对于存储系统,除了传统的性能、可靠性、安全性和可扩展性之外,还应考虑以下特性:
性能:AI工作负载对性能的可预测性和一致性要求极高。全闪存存储能提供低延迟和高带宽,是理想选择。可靠性与数据保护:存储系统应具备容错能力,防止数据丢失。安全性:采用最佳实践保护数据安全。K8s原生支持:考虑到Kubernetes在AI/ML领域的广泛应用,存储系统应与K8s无缝集成。加速MLOps:数据科学家应能自助访问存储、向量数据库和ML服务,加速模型开发。可扩展性:存储系统应能线性扩展,以满足不断增长的数据需求。简单性:易于配置和管理,减少运维负担。成本效益:存储成本应与容量成正比,且不影响性能。能效:存储系统应节能,以降低总体拥有成本。
总结 #
AI的迅猛发展给传统的IT基础设施带来了前所未有的挑战,尤其是数据存储与管理方面。这些挑战不仅新颖,而且与以往的IT问题存在显著差异。例如,AI平台架构师可能对IT环境中的操作流程和关键数据存储的特性并不熟悉,他们的经验往往集中在公共云环境。鉴于此,组织在部署和发展AI环境时,必须做出关键的IT决策。
其中,选择合适的存储类型是至关重要的。一个理想的数据存储平台应具备以下特点:
加速AI落地:从早期部署到成熟的AI生产环境,该平台能够显著缩短AI项目的交付周期。全方位性能:在性能、效率、可靠性、数据保护、扩展性和易用性等方面提供均衡且一致的解决方案,满足不同使用场景和成本要求。高级功能:支持快速部署、简化操作、无需复杂培训、最大化效率,并提供多维性能和多协议访问等高级特性。容器化友好:与主流容器编排框架(如Kubernetes)无缝集成,简化有状态应用程序的管理。显著缩短模型开发周期:能够帮助企业快速搭建一个能够训练和部署私有数据的AI环境,从而加速AI项目的落地。高置信度:系统的稳定性和可靠性能够最大程度地减少存储基础设施部署的时间,降低项目风险。