在熟练的VLSI物理实现工程师的手中,完美的timing不仅仅是一种可能性;它是被保证的。是的,每一次!
Slack #
SLACK是信号在电路节点上实际到达时间actual arrival time (AAT)和要求到达时间required arrival time (RAT)之间的差额。要求到达时间(RAT)是信号在不违反时间约束的情况下到达节点的最晚时间。相比之下,实际到达时间(AAT)是根据设计延迟,计算信号到达节点的实际时间。Slack可以是正的、负的或零。
Slack有两种。SETUP Slack(用于最坏的延迟路径)或HOLD Slack(用于最佳延迟路径),我们可以有两个公式来计算Slack:
Setup Slack = 所需到达时间(RAT)—实际到达时间(AAT)
Hold Slack = 实际到达时间(AAT)—所需到达时间(RAT)
- 正Slack意味着设计是按照规格工作的,并且有更多的时序余量margin。
- 零Slack意味着设计恰好满足所需的规格,并且没有时序余量margin。
- 负Slack意味着设计没有达到指定的时序要求,有时序违例timing violation。
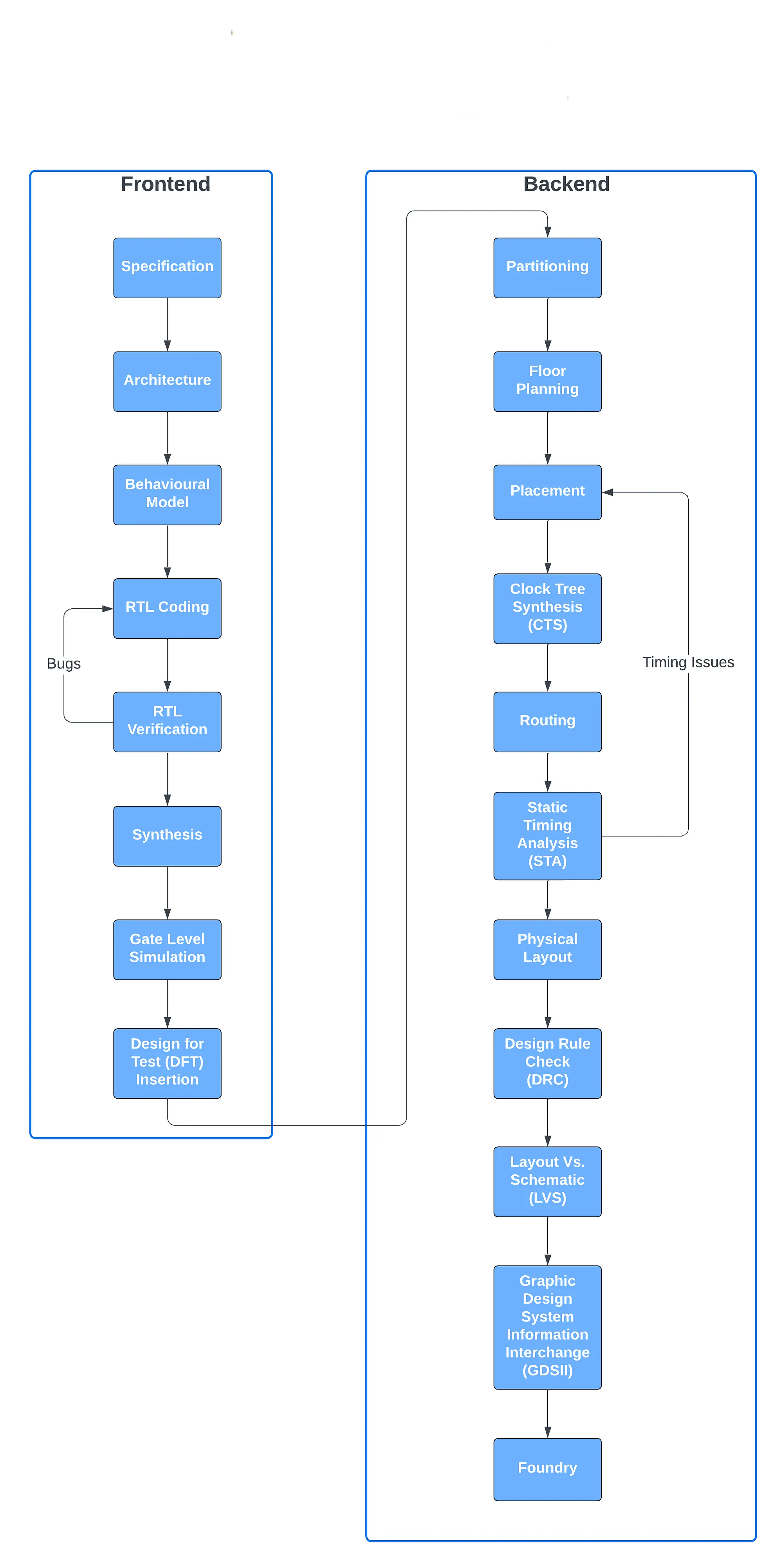
让我们来看看寄存器到寄存器时序slack分析的一个例子。它也可以称为触发器到触发器时序分析。时序分析主要有四种类型的路径。这些是:
- input到output
- input到register
- register到output
- register到register
但是,为了使事情易于理解和简单,我们首先以register到register时序分析为例。
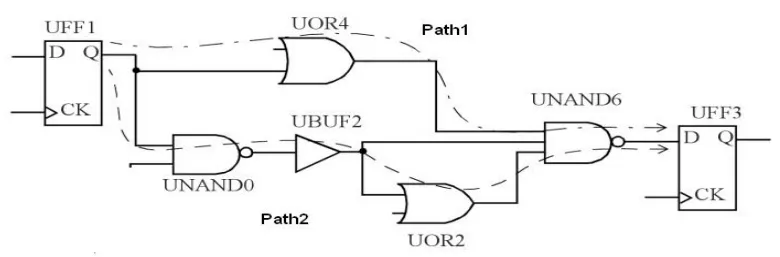

在这里,UFF1被称为launch flop,因为它启动/产生数据,UFF3被称为Capture flop,因为它捕获了Launch Flop启动的数据。这只是一些花哨的英语词汇而已,可以不用理会。
clk到Q延迟[Tclk→q]:检测到时钟边沿后,触发器需要一些时间来处理输入数据并传播正确的输出。这个时间间隔被称为clk到Q延迟(Tclk→q)。它是指在检测到时钟信号边沿后,触发器的输出(Q)改变状态所需的时间。
path1和path2的延迟计算如下。
- path1的延迟=Tpropogation(UOR4)+Tpropogation(UNAND6)=5ns+6ns=11ns
- path2 = Tpropogation(UNAND0) + Tprogation(UBUF2) + Tpropogation(UOR2) + Tpropogation(UNAND6) = 6ns + 2ns + 5ns + 6ns = 19ns
因此,path2是最长的路径,延迟最高,path1是最短路径,延迟最小或最佳。
register到register的 setup Slack #
选择最大延迟路径进行setup分析。在这里,也就是path2。
在这里,假设时钟周期(Tclk)=30ns,
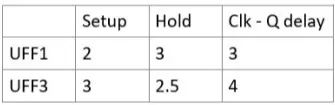
实际到达时间 = Tclk→q(UFF1) + Tpropogation(UNAND0) + Tpropogation(UBUF2) + Tpropogation(UOR2) + Tpropogation(UNAND6) = 3ns + 19ns =22ns
所需到达时间 = Tclk — Tsetup(UFF3) = 30ns — 3ns = 27ns
setup Slack = 所需到达时间 — 实际到达时间 = 27ns — 22ns = +5ns(正数)
在这里,由于Setup Slack值为正值,因此没有违反setup timing!
Setup Slack的负值意味着数据在setup timing时间窗口之外到达。
register to register hold Slack 选择最佳延迟或最小延迟路径进行hold分析。在这里,也就是path1。
在这里,假设时钟周期相同,即Tclk = 30ns,
-
实际到达时间 = Tclk→q(UFF1) + Tpropogation(UOR4) + Tpropogation(UNAND6) = 3ns + 11ns = 14ns
-
所需到达时间 = Thold(UFF3)=2.5ns
-
hold slack = 实际到达时间 — 要求到达时间 = 14ns — 2.5ns =+ 11.5ns(正数)
在这里,由于hold Slack值为正,因此没有违反hold timing!
Hold Slack的负值意味着信号值从一个寄存器传播到下一个寄存器的速度太快。
最常见的hold timing修复是在寄存器之间添加buffer,这增加了满足hold timing约束的组合逻辑延迟。
有趣的是,时钟频率不影响hold timing。
如何优化时序 #
可以使用几种技术,如sizing、buffering和retiming。
- sizing包括改变晶体管的尺寸(特别是宽度),以调整其驱动强度和延迟。
- buffer包括插入buffer或inverter,以提高信号强度并减少延迟。
- retiming是一种在设计中重新定位触发器的技术。
所有这些技术都可以使用设计工具手动或自动完成。最终,这些技术可以平衡slack,改善长互连和扇出,优化setup和hold时间。
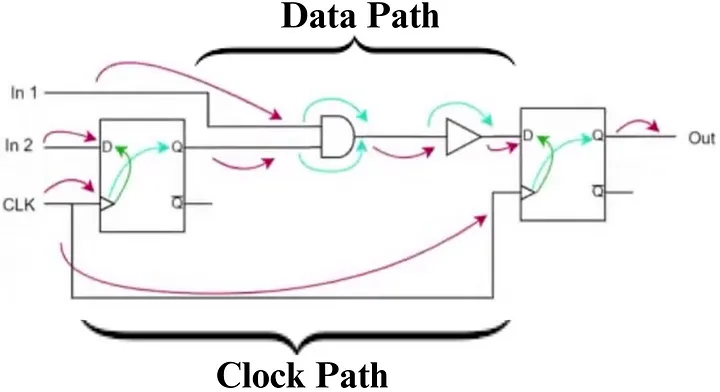
Slack分析中的数据路径和时钟路径 #