GPU vs LPU for AI: Key Differences and Use Cases
Generative AI models have scaled into the billions and trillions of parameters, pushing far beyond what traditional CPUs can handle. As a result, specialized accelerators have become essential.
For years, GPUs have dominated AI workloads thanks to their massive parallelism. But a newer contender—the LPU (Language Processing Unit)—is emerging, designed specifically for sequential AI workloads like natural language processing (NLP).
This article breaks down the architectural differences, strengths, and real-world use cases of both.
🧠 GPU Architecture #
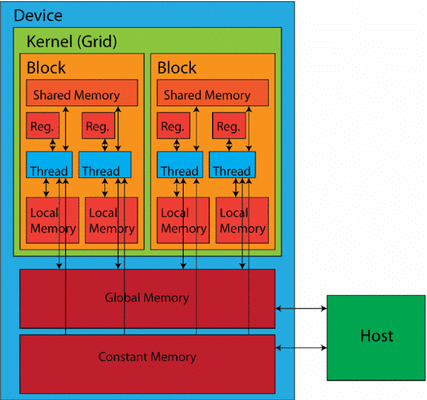
A GPU is built around massively parallel compute units, often called:
- Streaming Multiprocessors (SMs)
- CUDA cores (NVIDIA terminology)
Each compute unit contains:
- Multiple processing cores
- Registers and shared memory
- Control and scheduling logic
These cores execute thousands of threads simultaneously, making GPUs ideal for data-parallel workloads like matrix operations in deep learning.
🔧 Key Design Elements #
- Parallel execution model (SIMT)
- Tensor / Matrix cores for AI acceleration
- Deep memory hierarchy:
- Registers (fastest)
- Shared memory
- Global memory (largest, slower)
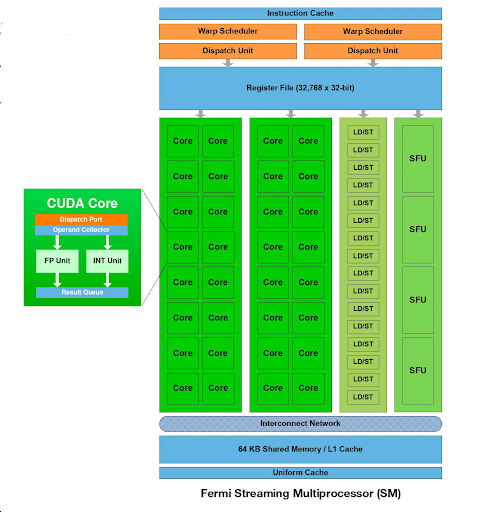
🔗 Communication and Scaling #
GPUs rely on advanced interconnects:
- Bus-based systems (simple but limited)
- Network-on-Chip (NoC) (scalable, high bandwidth)
- Point-to-Point (P2P) links (low latency)
Topologies include:
- Crossbar
- Mesh
- Ring
They also connect to CPUs via PCIe, enabling system-level integration.
⚡ Performance Strategy #
- Thread-Level Parallelism (TLP)
- Data-Level Parallelism (DLP)
- Deep pipelining
👉 Result: GPUs excel at high-throughput, parallel workloads.
🧩 LPU Architecture #
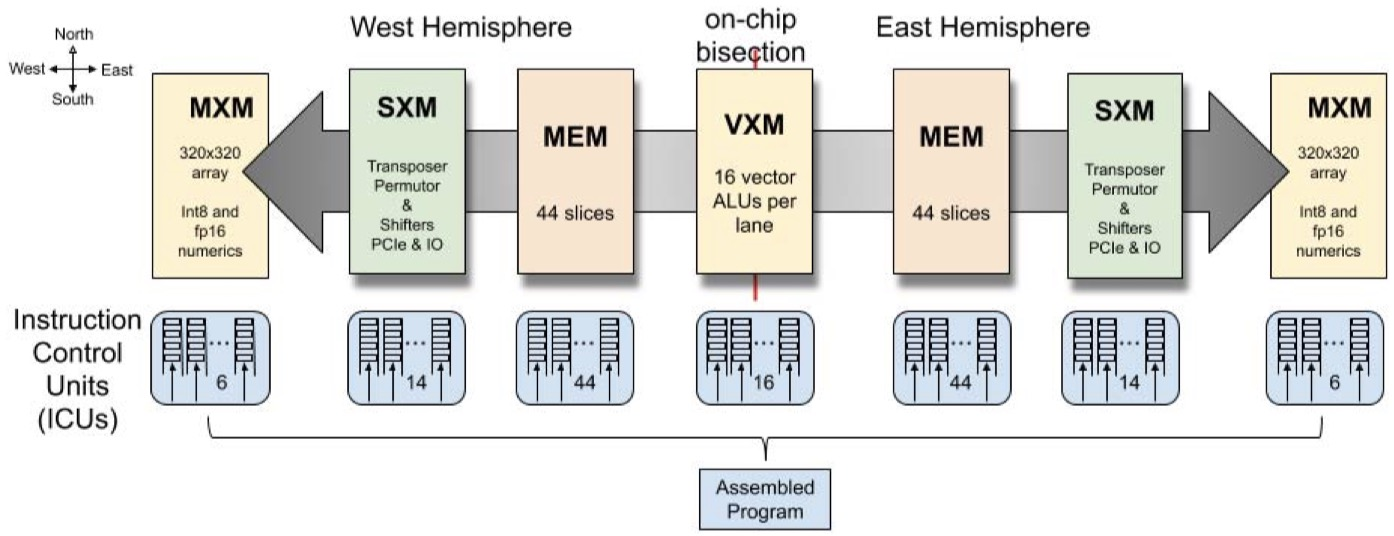
The LPU (Language Processing Unit)—notably from Groq—is designed for a different goal:
👉 Ultra-fast, deterministic execution of sequential workloads
Instead of massive parallelism, LPUs use a Tensor Streaming Processor (TSP) architecture optimized for token-by-token processing, which is critical for NLP.
🔍 Core Design Philosophy #
- Deterministic execution (no scheduling overhead)
- Optimized for sequential data flow
- Eliminates irregular memory access penalties
This makes LPUs highly efficient for language models and inference pipelines.
🧠 Memory and Data Flow #
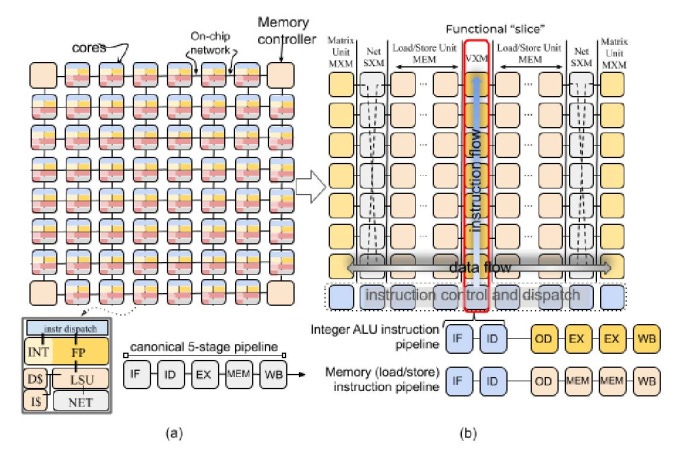
LPUs use a carefully tuned memory hierarchy:
- Registers (fastest access)
- L2 cache
- Main memory (model storage)
- High-bandwidth on-chip SRAM
The key advantage is predictable data movement, which minimizes latency—crucial for real-time AI systems.
⚙️ Software Stack #
LPUs are supported by a dedicated software ecosystem:
- Compiler optimized for NLP graphs
- Compatibility with frameworks like TensorFlow and PyTorch
- Runtime for scheduling and memory management
While not as mature as GPU ecosystems, LPU software is highly optimized for its niche.
⚔️ GPU vs LPU: Performance Comparison #
| Feature | GPU | LPU |
|---|---|---|
| Architecture | Massively parallel | Sequential / deterministic |
| Best Use | Training + general AI | NLP inference |
| Strength | Versatility, ecosystem | Low latency, efficiency |
| Weakness | Inefficient for irregular workloads | Limited ecosystem |
| Memory | Multi-tier hierarchical | Optimized for model streaming |
| Optimization | Parallelism + pipelining | Deterministic execution |
🚀 Real-World Performance #
- LPUs can reach extremely high inference speeds (e.g., hundreds of tokens/sec)
- GPUs handle:
- Training large models
- Vision and multimodal AI
- Scientific computing
👉 Key difference:
- GPU = general-purpose AI engine
- LPU = specialized inference engine
🧩 When to Choose GPU vs LPU #
✅ Choose a GPU if you need: #
- End-to-end AI pipeline (training → inference → deployment)
- Support for multiple workloads (vision, speech, analytics)
- Mature ecosystem (CUDA, libraries, tooling)
✅ Choose an LPU if you need: #
- Ultra-fast NLP inference
- Low latency for real-time applications (chatbots, assistants)
- Deterministic, predictable performance
🏁 Final Thoughts #
The rise of LPUs doesn’t replace GPUs—it complements them.
- GPUs remain the backbone of AI development and training
- LPUs push the boundaries of real-time language inference
👉 The future of AI infrastructure will likely be heterogeneous, combining both architectures:
- GPUs for training and general compute
- LPUs (or similar accelerators) for high-speed inference
Choosing the right hardware ultimately depends on your workload:
parallel vs sequential, general vs specialized, throughput vs latency.