CUDA is the core parallel computing platform used by modern NVIDIA GPUs. By allowing thousands of threads to execute simultaneously, CUDA dramatically accelerates compute-heavy workloads and has become a cornerstone of high-performance computing worldwide. Today, CUDA powers applications in AI, deep learning, scientific simulation, graphics, financial modeling, and more.
What Is CUDA? #
CUDA stands for Compute Unified Device Architecture. It is not just a GPU library—CUDA is an entire parallel computing platform and programming model developed by NVIDIA. It provides:
- A unified programming model
- Optimized GPU libraries
- Development tools
- A runtime environment
- Low-level device drivers
Together, these components allow developers to run general-purpose code on NVIDIA GPUs to achieve major performance gains.
In practice, the term CUDA often refers to the ecosystem as a whole and the GPU-accelerated C/C++ or Python code written to run on NVIDIA hardware.
Key Components of CUDA #
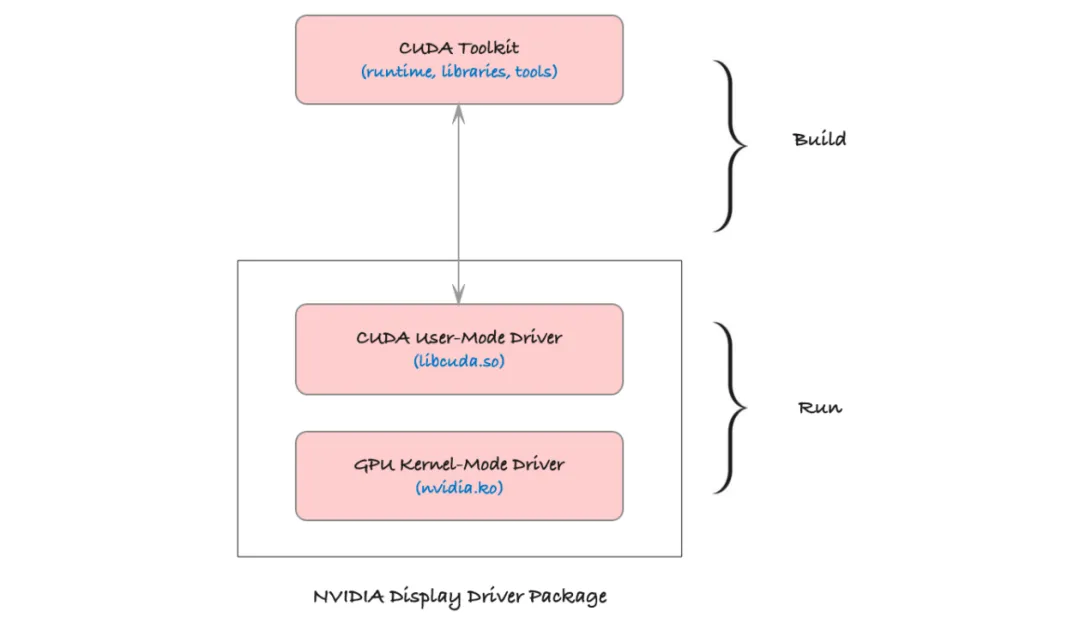
-
CUDA C/C++
An extension of C++ that enables developers to write GPU kernels and manage parallel threads using familiar syntax. -
CUDA Driver
Provides low-level interfaces that manage memory transfers, GPU resources, and hardware communication. -
CUDA Runtime (cudart)
A higher-level API simplifying GPU memory management, kernel launching, and synchronization. -
CUDA Toolchain (ctk)
Includes compilers, linkers, profilers, and debuggers that translate CUDA C/C++ into GPU-executable code and help optimize performance.
Useful CUDA Environment Variables #
$CUDA_HOME — typically /usr/local/cuda or /usr/local/cuda-X.X
$LD_LIBRARY_PATH — should include $CUDA_HOME/lib
$PATH — should include $CUDA_HOME/bin
With this full toolchain, developers can systematically harness NVIDIA GPUs for high-efficiency parallel computing.
How CUDA Works #
Modern NVIDIA GPUs contain thousands of small compute units called CUDA Cores. These cores operate in parallel, making GPUs extremely efficient at processing workloads that can be divided into many small tasks.
1. Parallel Processing #
CUDA decomposes large computational tasks into thousands of lightweight threads, enabling massive parallelism and far greater throughput than serial CPU execution.
2. Thread and Block Architecture #
CUDA organizes work into:
- Threads – the smallest units of work
- Blocks – groups of threads
- Grids – collections of blocks
This hierarchy helps the GPU schedule and execute tasks efficiently across thousands of cores.
3. SIMD Execution #
CUDA uses a SIMD (Single Instruction, Multiple Data) execution approach. This allows one instruction to run simultaneously across many data elements, making it ideal for:
- Deep learning training
- Vector and matrix operations
- Physics simulation
- Image processing
The CUDA Programming Model #
CUDA programs contain two main parts:
1. Host Code (runs on CPU) #
The host code is responsible for:
- Transferring data between CPU and GPU
- Allocating and freeing GPU memory
- Configuring and launching kernels
- Managing program flow
This part of the program uses CUDA Runtime APIs like cudaMalloc, cudaMemcpy, and kernel launch commands.
2. Device Code (runs on GPU) #
Device code contains kernel functions, which are marked with __global__ and run across many parallel threads.
Key concepts:
- Kernel functions — GPU-executed functions with no return value
- Thread indices — variables like
threadIdxandblockIdxdetermine each thread’s work - Parallel memory optimization — reducing global memory access and maximizing shared memory usage is critical for performance
3. Kernel Launch #
CUDA uses a unique syntax to launch GPU kernels:
kernel<<<numBlocks, threadsPerBlock>>>(parameters);
Developers control how many threads and blocks are created, which affects performance and parallelism.
CUDA supports:
- Asynchronous execution
- Stream-based parallelism
- CPU/GPU overlap
These features enable highly efficient execution pipelines.
CUDA Memory Hierarchy #
CUDA provides several memory types, each suited for different purposes.
1. Global Memory #
- Largest storage (GB-level)
- Accessible by all threads and CPU
- Slowest access
- Ideal for large datasets
Example (matrix multiplication):
__global__ void matrixMultiplication(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0;
for (int i = 0; i < N; ++i) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}
2. Shared Memory #
- Much faster than global memory
- Shared within a block
- Limited capacity (e.g., 48 KB per block)
- Ideal for reused data or block-level caching
Example:
__shared__ float sharedA[TILE_SIZE][TILE_SIZE];
__shared__ float sharedB[TILE_SIZE][TILE_SIZE];
3. Local Memory #
- Private to each thread
- Stored in global memory
- Used for spilling registers or large local variables
Example:
int localVariable = 0;
4. Constant & Texture Memory #
Optimized read-only memory types:
- Constant memory – small and cached
- Texture memory – ideal for 2D/3D spatial access patterns (images, grids)
Example:
__constant__ float constData[256];
cudaArray* texArray;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaMallocArray(&texArray, &channelDesc, width, height);
Summary #
CUDA unlocks the full parallel computing capability of NVIDIA GPUs, enabling enormous speedups for compute-heavy workloads. With CUDA’s programming model, memory hierarchy, and extensive toolchain, developers worldwide can efficiently accelerate applications in AI, HPC, simulation, and data analysis.