今天,在超级计算 2024 大会上,许多公司宣布了他们最新的 AI、HPC 和超级计算产品。这些公司中首屈一指的当然是 NVIDIA,该公司最重大的新产品发布是 GB200 NVL4。不过,我们稍后会了解 GB200 NVL4 是什么;首先,让我们谈谈绿色团队还宣布用于 AI 和 HPC 应用的 H200 NVL。

H200 NVL 是 PCIe 附加卡,带有 H200 Hopper 加速器,顶部带有 NVLink 连接器。这样你就可以使用 NVLink 桥接器——就像我们以前对 SLI 显卡所做的那样——重点是使用 900 GB/秒的 NVLink 连接可以让最多四个 GPU 保持内存一致性,换句话说,你可以将所有四个 GPU 的内存组合成一个大池,而不必复制每张卡本地内存中的数据来处理它。
NVIDIA 将 H200 NVL 描述为“主流企业服务器的 AI 加速”,并表示四个 GPU(每个 GPU 有 141 GB 的 RAM)的封装将“适合任何数据中心”。正如 NVIDIA 自己指出的那样,超过 70% 的企业部署都是风冷的,功率低于 20 千瓦,这使得部署大量夹层 GPU(如 H200 的 SXM 版本)变得更加困难。因此,我们有这些 600W GPU 用于标准 PCIe 插槽。

NVIDIA 的全新 GB200 NVL4 模块 #
既然我们已经讨论了 H200 NVL,那么让我们来谈谈 GB200 NVL4。GB200 NVL4 几乎是 H200 NVL 的典型对立面——它将两个 Grace CPU 和四个 Blackwell B200 GPU,以及每个处理器的各自内存和电源传输硬件组合到单个 PCB 上。每个处理器都通过 NVLink 连接到所有其他处理器,总共提供 768GB 的 HBM3 内存。与 Grace CPU 的 960GB LPDDR5X RAM 相结合,每个主板总共有 1.5TB 的 RAM。
虽然与现有的 GB200 超级芯片相比,这似乎是一种更优越的解决方案,因为它本质上是两个连接在一起的,但有一个关键的区别,那就是 GB200 NVL4 没有板外 NVLink 功能。GB200 超级芯片可以与其他 GB200 超级芯片一起部署,形成一种超级 GPU,使用板之间的 NVLink 连接来保持内存一致性。

GB200 NVL4 没有这种能力。相反,板外通信由 Infiniband 或以太网处理,可能是 NVIDIA 自己的 Spectrum-X 以太网。如果我们要推测,这可能是 NVIDIA 为更好地与拥有自己的互连技术的 HPC 提供商(如 HPE)集成而采取的举措。
不过,这些 GPU 的功能并不比原来的 GB200 弱。 GB200 NVL4 的总板功率预计为 5,400 瓦,即 5.4 千瓦。将其中几个放在机架中,您就已经突破了 20 千瓦的障碍。NVIDIA 表示,与 GH200 NVL4 部件相比,GB200 NVL4 板的模拟能力提升了 120%,AI 训练和推理工作负载提升了 80%。
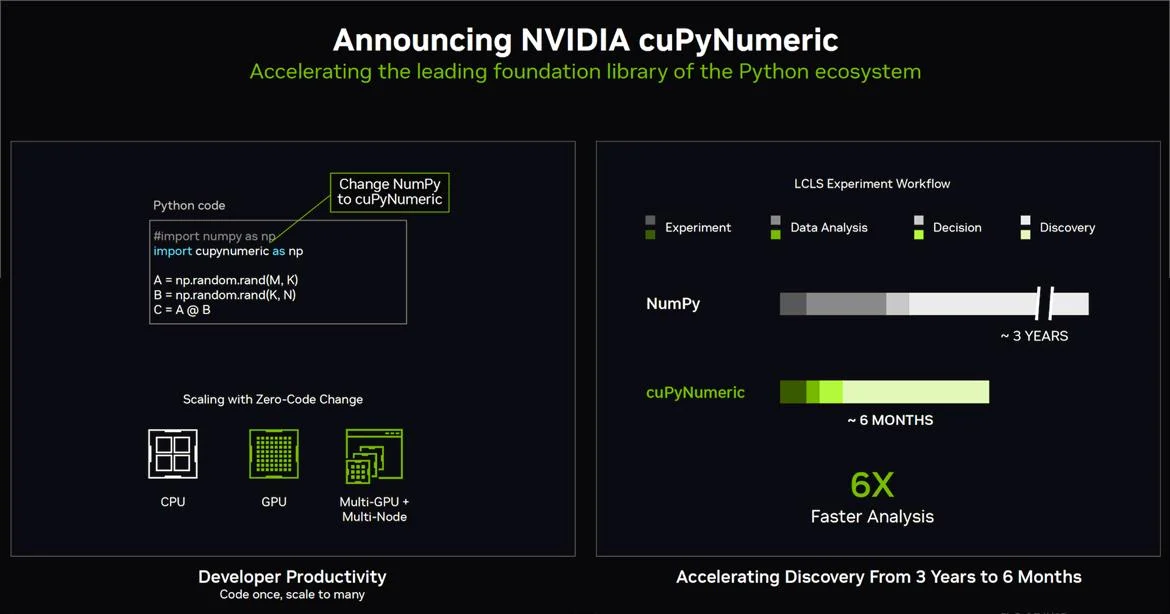
NVIDIA 在 Supercomputing 2024 上发布了许多其他公告,但它们大多是涵盖广泛市场和用例的软件更新。如果您是 AI 开发人员,您可能已经知道它们,但可以说最大的一个是 NVIDIA 有一个流行的 NumPy 库的嵌入式 GPU 加速替代品,称为 CuPyNumeric,它声称为 SLAC 国家加速器实验室的数值分析提供了 6 倍的性能提升。

NVIDIA 强调,其发布周期为一年,明年计划发布 Blackwell Ultra,这是现有 Blackwell GPU 的修订版,板载 HBM3e 内存增加了一倍,并含糊地承诺“更多 AI FLOPS”。明年显然还会发布升级的网络硬件,而我们显然会在 2026 年看到 Grace 和 Blackwell 的继任者,即 Vera CPU 和 Rubin GPU。