South Korea–based Panmnesia, a company focused on CXL (Compute Express Link) memory technologies, is pushing for a unified memory and interconnect design to power the next generation of AI superclusters. The company believes that future AI workloads demand both GPU node memory sharing and fast inter-GPU networking, achieved by combining CXL with UALink/NVLink architectures.
A Technical Report on the Future of AI Infrastructure #
Panmnesia’s CEO, Dr. Myoungsoo Jung, has released a 56-page technical report titled “Compute Can’t Handle the Truth: Why Communication Tax Prioritizes Memory and Interconnects in Modern AI Infrastructure.”
The report highlights:
- The growth of AI models and why current compute-centric infrastructures struggle to scale.
- The limitations of rigid GPU-centric architectures, such as communication overhead and low utilization.
- The role of emerging interconnect and memory technologies—CXL, NVLink, UALink, and HBM—in solving these challenges.
Jung notes:
“No single fixed architecture can fully satisfy all the compute, memory, and networking demands for large-scale AI. The best solution is to integrate CXL with accelerator-focused interconnects like NVLink and UALink.”
Breaking Down the Report: Three Key Parts #
-
Trends in AI and Data Center Architectures
Explains how workloads like chatbots, image generation, and video processing rely on sequence models (RNNs → LLMs) and why current infrastructures bottleneck performance. -
CXL Composable Architectures
Shows how CXL 3.0—with multi-level switching, advanced routing, and memory coherence—can reshape data center memory architectures. Panmnesia has already developed a CXL 3.0–compliant prototype, tested on RAG and deep learning recommendation models (DLRMs). -
Beyond CXL: Hybrid Link Architectures
Introduces “CXL over XLink”, where CXL handles memory pooling and coherence, while XLink (UALink + NVLink) delivers low-latency accelerator-to-accelerator communication.
Why Combine CXL and XLink? #
- CXL → Expands memory capacity, provides system-wide coherence, and enables disaggregated, composable memory pools.
- XLink (UALink + NVLink) → Optimized for direct GPU-to-GPU transfers with ultra-low latency.
- Unified Approach (CXL over XLink) → Bridges the gap, creating:
- Accelerator-centric clusters for rapid intra-cluster GPU communication.
- Tiered memory architectures with local high-performance memory and scalable pooled memory.
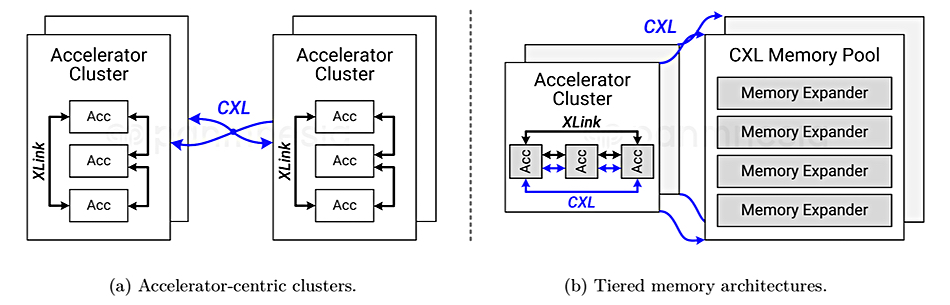
Toward Scalable AI Superclusters #
Dr. Jung envisions a scalable tiered memory hierarchy for AI superclusters:
- Tier 1: High-performance local memory managed by XLink + coherence-centric CXL.
- Tier 2: Composable memory pools enabled by CXL for large-scale data handling.
This hybrid model is designed to meet the unique performance needs of LLMs, inference, RAG, and recommendation systems—paving the way for future-proof AI infrastructure.
Final Thoughts #
Panmnesia’s work underscores a growing industry realization: AI progress depends as much on memory and interconnects as it does on compute.
By unifying CXL’s composability with NVLink/UALink’s accelerator speed, Panmnesia is proposing a new blueprint for AI data centers that could define the next generation of superclusters powering large-scale AI applications.