NVIDIA GB200 NVL4: Quad Blackwell Superchip Explained

At Supercomputing 2024, NVIDIA introduced a new class of AI and HPC hardware, headlined by the GB200 NVL4. This system represents a significant evolution in GPU-CPU integration, designed to deliver massive compute density and unified memory for next-generation workloads.
Before diving into the GB200 NVL4, it’s helpful to understand another product announced alongside it: the H200 NVL, which targets more traditional enterprise deployments.
🚀 H200 NVL: Scalable AI for Enterprise Servers #
The H200 NVL is a PCIe-based accelerator built on the Hopper architecture. It features NVLink connectors that allow multiple GPUs to be interconnected with high bandwidth.

Key characteristics:
- PCIe add-in card form factor
- NVLink bandwidth up to 900 GB/s
- Supports multi-GPU memory pooling
- Designed for air-cooled data centers (<20 kW racks)
- Each GPU includes ~141 GB memory
With NVLink bridging, up to four GPUs can operate as a single coherent memory system, reducing data movement overhead and improving performance for large AI workloads.
NVIDIA positions the H200 NVL as a practical, deployable solution for mainstream enterprise environments.
🧠 GB200 NVL4: A Fully Integrated AI Superchip #

The GB200 NVL4 takes a radically different approach. Instead of modular PCIe cards, it integrates multiple processors into a single board:
- 2× Grace CPUs
- 4× Blackwell B200 GPUs
- Full NVLink interconnect between all components
This creates a tightly coupled system with extremely high bandwidth and low latency between CPUs and GPUs.
Memory Architecture #
- 768 GB HBM3 (GPU memory)
- 960 GB LPDDR5X (CPU memory)
- Total: ~1.5 TB unified memory per board
This unified memory design enables large-scale AI models and simulations to run without constant data transfers between devices.
⚡ Key Architectural Differences #
While the GB200 NVL4 appears similar to combining multiple GB200 Superchips, there is a crucial distinction:
❌ No Off-Board NVLink #
- GB200 NVL4 does NOT support external NVLink scaling
- Cannot form multi-board memory-coherent clusters via NVLink
✅ External Communication via Networking #
- Uses InfiniBand or Ethernet (Spectrum-X)
- Better alignment with existing HPC infrastructure
This design likely reflects NVIDIA’s intent to integrate more seamlessly with enterprise and HPC ecosystems, where standardized networking is preferred over proprietary interconnect scaling.
🔥 Performance and Power #
The GB200 NVL4 is an extremely power-dense system:
- Total board power: ~5.4 kW
- Easily exceeds 20 kW per rack in multi-board deployments
Performance improvements vs. previous generation (GH200 NVL4):
- +120% simulation performance
- +80% AI training & inference performance
This positions the GB200 NVL4 as a top-tier solution for large-scale AI training, simulation, and HPC workloads.
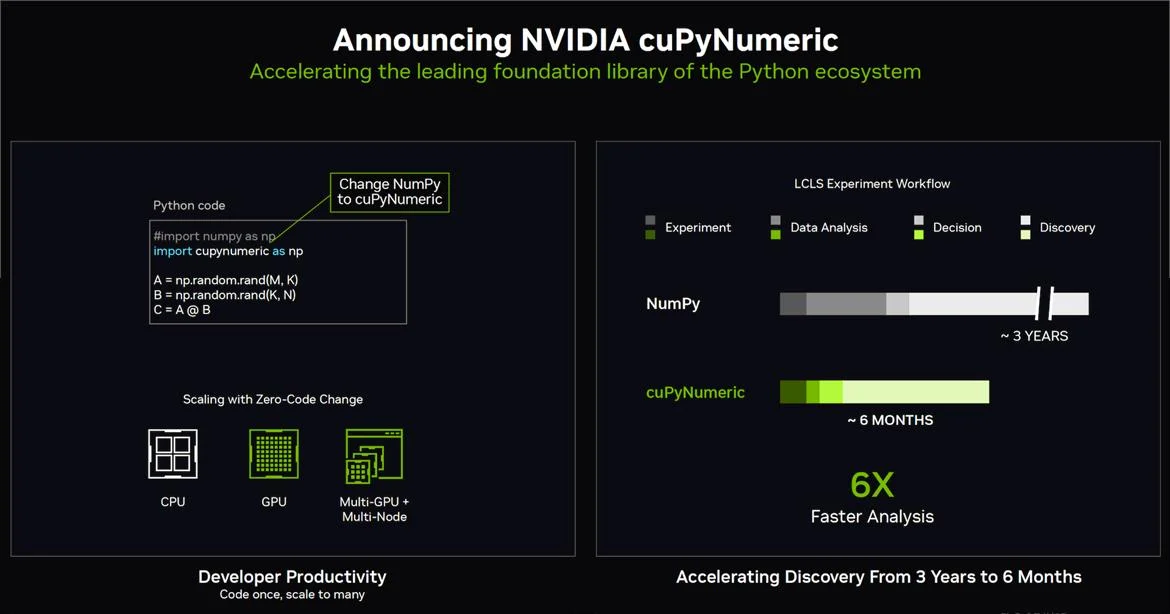
🧮 Software Ecosystem: CuPyNumeric #

Beyond hardware, NVIDIA also introduced updates to its software ecosystem. One standout is CuPyNumeric, a GPU-accelerated alternative to NumPy.
Highlights:
- Drop-in replacement for NumPy
- Designed for GPU acceleration
- Reported 6× speedup in numerical workloads
- Proven in real-world environments like SLAC
This reinforces NVIDIA’s strategy of full-stack optimization, combining hardware and software for maximum performance.
🔮 Roadmap: What Comes Next? #
NVIDIA continues to iterate rapidly on its AI hardware roadmap:
- 2025 → Blackwell Ultra (more memory, higher AI FLOPS)
- 2026 → Next-gen Vera CPU + Rubin GPU
- Annual release cadence for continuous performance gains
This aggressive roadmap highlights NVIDIA’s commitment to staying ahead in the AI and HPC space.
🧩 Final Thoughts #
The GB200 NVL4 represents a major shift in system design:
- Deep CPU-GPU integration with unified memory
- Massive on-board bandwidth via NVLink
- Trade-off: no NVLink scaling across boards
- Optimized for rack-scale AI and HPC deployments
Meanwhile, the H200 NVL offers a more flexible and deployable alternative for traditional data centers.
👉 Bottom line: NVIDIA is no longer just building GPUs—it’s building complete AI computing platforms, redefining how large-scale workloads are deployed and executed.